

Let's say you've just built a new feature, but it's not ready for a full release just yet. So, you decide to test it with a small group of people.

You can go about it in two ways - deterministic or random. The first way lets you specify people by name, email, company or any other attribute you know about them. The latter uses fancy math and probability to randomly assign users into groups. Let's see how you'd accomplish both using ConfigCat's feature flag services. For context, ConfigCat is a developer-centric feature flag service with unlimited team size, awesome support, and a reasonable price tag.
Targeting Specific Users
Say you want to target people from your own company so your QA team can do manual testing of the new navigation. Well, you'd simply log in to your ConfigCat dashboard and set up targeting rules using the aptly named TARGET SPECIFIC USERS feature. If everyone you wish to target is logged into your app using their email address ending in "@mycompany.com", use the Email Attribute with the CONTAINS Comparator, and "@mycompany.com" as the Comparison value. Setting the Served value to ON will enable anyone using that email to get the feature while excluding everyone else. You can find detailed documentation here.
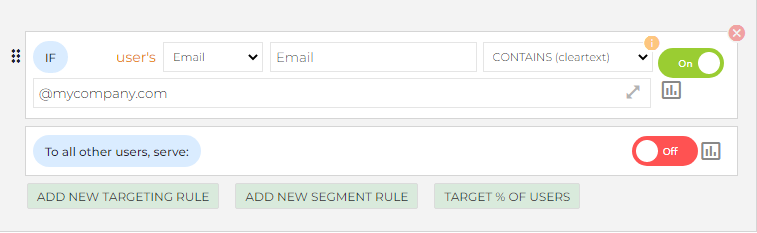
Then, from your code, you would need to pass the User Object to a getValue call and use the boolean that it returns:
const client = configcat.createClient("YOUR SDK KEY HERE");
const user = new User("[email protected]");
// using the promise-based version of getValue here
client.getValueAsync(
"newNavigation", // Feature name set up in the Dashboard
false, // Default value
user) // User object containing the email address
.then((isFeatureEnabled) => {
if (isFeatureEnabled) {
// show new navigation
}
else {
// show old navigation
}
});
This will return true for [email protected], but false for [email protected]. You can use other comparison attributes to turn features on and off.
Don't Worry About Privacy
Your users' data never leave their devices because the ConfigCat SDK evaluates targeting rules locally. After SDK initialization, your application downloads a configuration file from the ConfigCat CDN. The configuration is then cached on the device and is the source of truth for all getValue calls. The configuration is refreshed at regular intervals (every 60 seconds by default) by making additional requests to the CDN.
This locally cached configuration contains all the feature flags and their targeting rules which you set up in the dashboard, so there is no need to send the user's data to ConfigCat servers. However, the targeting rules could contain sensitive information, like the email address of a specific person you want to include/exclude in your testing. This information could be exposed in a front-end application; fortunately, ConfigCat has a solution for this problem.
When dealing with sensitive information, there are two special Comparators available in the dashboard: IS ONE OF (Sensitive) and IS NOT ONE OF (Sensitive) (check the docs for details). Any information that is using these Comparators will be hashed by the SHA1 cryptographic hash function before it is sent to your application. This will turn "[email protected]" into "ad76509bd71dce684b8fd09f3e6b7b3f72df035b". On the application end of things, the SDK will do the same transformation locally and compare it to the value in the targeting rule. You can verify this here. And the best part - your calls to getValue will remain the same, so there's no need to change your code in any way.
If this doesn't put you at ease, you can always use a unique user ID or check sensitive info in your backend code, which won't leak information to the frontend app.
Performing a Random Test With Percentage-based Targeting
Let's say you're trying to optimize your landing page, and you decide to make some changes. You're aware that simply relying on your intuition isn't enough and so you decide to get some hard data to support (or refute) your hypothesis. This is where A/B testing comes in.
You decide that 50% of your audience will get the new version and 50% will get the old version, so you can track whether there is a significant change in user behavior between the two versions. Setting this up with ConfigCat is a breeze.
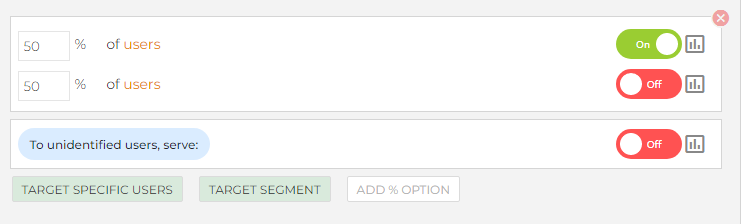 In your dashboard, select the
In your dashboard, select the TARGET % OF USERS option. Input 50% for both toggle options, and you're all set. On the code side, just use getValue as before. You can then analyze the data with an analytics platform. Check out this tutorial for a more detailed look at A/B testing with ConfigCat.
How Are Percentages Calculated?
Percentage-based targeting is also evaluated locally on the user's device, just like specific targeting. The SDK uses the SHA1 function again, this time not for information hiding (because nothing about the user travels either way) but for generating a pseudo-random string of characters.
The SDK concatenates the user's identifier with the feature flag's key and hashes it with the SHA1 function. It then takes the first seven(7) digits of the hashed value, converts it into an integer, and finally coerces it to a number between 0-100 using the modulo operator. You can check the evaluation code here. Let's see an example.
Using isFeatureEnabled as the feature flag's key and [email protected] as the identifier, the SDK:
- concatenates
isFeatureEnabledwith[email protected]to form[email protected] - hashes
[email protected]into1b0f1b6f496727d530ae5235fd78682c5ea121a8 - takes
1b0f1b6from the beginning of the hash - converts
1b0f1b6to the integer28373430 - performs the modulo operation:
28373430 % 100 = 30
Since we are splitting users into two groups of 50% each, Jane will end up in the first group (she ended up at the 30th percent) and will thus receive the new version of the page.
It is possible to have more than two groups to which you can serve variations of a feature. In this case, you use text and number values instead of on/off toggles. See the docs for more details.
It is important to note that because ConfigCat adds the feature flag's key to your user's identifier, you don't test different features with the same group of users all the time.
Percentages Are Sticky
The outputs of the SHA1 function seem random, but they're actually determined by a specific series of mathematical operations. These ensure three important things:
- outputs are unpredictable - even a small change like turning "jane" into "Jane" will have a wildly different output, so even people with emails from the same company aren't any more likely to end up in the same group.
- outputs are evenly distributed - any user is equally likely to end up in any of the groups, so you won't have too much data for one version and not enough for others.
- the same input always has the same output - if the output were truly random, the same user would keep switching between groups on different devices, which would lead to a bad user experience.
The last feature of this approach ensures that the same user always has the same experience, since the described calculation method is the same across all platforms. Furthermore, this calculation can be performed as many times as necessary, e.g. on fresh installs or after cache deletion, and the result will always be the same, without the need to save or sync the result in any way.
The only way to change the experience for the user is to set your percentages differently. In our example, if you change from a 50-50 split to 20-80, Jane will suddenly see the old version (30 being greater than 20). However, if you change the percentage of the first group to 30 and above, she'll be back on the new version.

Summary
Hopefully, you now have a better understanding of ConfigCat's targeting features. ConfigCat supports simple feature toggles, user segmentation, and A/B testing and has a generous free tier for low-volume use cases or those just starting out. Next time you're doing a canary release or a beta test, you can comfortably use the targeting features while knowing how things work under the hood. Here's a quick recap of the things we covered:
- Target specific users of your app with the
TARGET SPECIFIC USERSfeature. - Secure data for your frontend by using sensitive comparators with
TARGET SPECIFIC USERS. - Use percentage-based targeting to distribute your users randomly across two or more groups.
- Don't worry about the percentage values changing, percentage-based targeting was designed in a way that it works the same on all platforms and ConfigCat SDKs.
Resources
Here are some resources you might find helpful.
You can stay up to date with ConfigCat on Twitter, Facebook, GitHub, and LinkedIn.